Java Map 集合

put会覆盖之前的value并返回原来的value
遍历方法
键找值
keySet()
Set<String> strings = map.keySet();
for (String string : strings) {
String value = map.get(string);
System.out.println(value);
}
Iterator<String> iterator = strings.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(map.get(next));
}
strings.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(map.get(s));
}
});
键值对
entrySet()
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while(iterator.hasNext()){
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey()+"::"+next.getValue());
}
HashMap

put方法在元素相等时仍然是覆盖, 否则和HashSet一样存成链表转为红黑树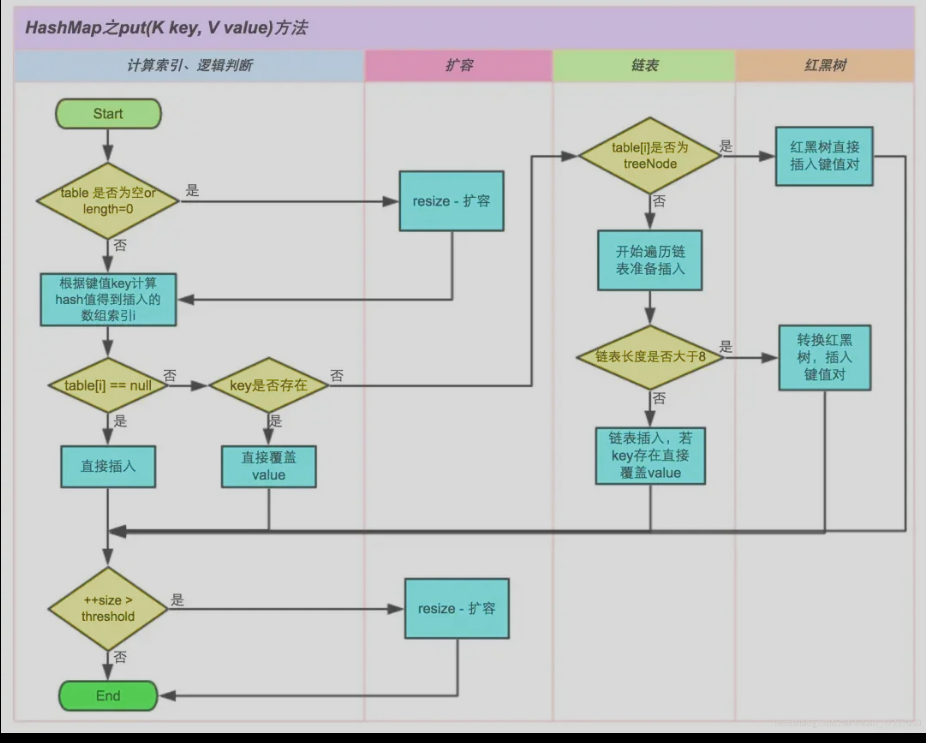
LinkedHashMap

TreeMap

两种比较规则
- 使用第一种时, 要求
map的key是自定义类型
TreeMap<Student,String> treeMap = new TreeMap<>()
Comparator泛型是key的类型, 比较只是比较key
TreeMap<Integer,String> treeMap = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
下面补充说明“重哈希定位更高效”的含义。
当 HashMap 中的元素数量超过了阈值(默认是容量的 0.75 倍)时,就会触发扩容。扩容 = 数组容量翻倍 + 所有元素重新计算位置,这个过程就叫做 rehash(重哈希)。
那为什么容量是 2 的 n 次方会让重哈希更高效?
1. 不用重新计算完整哈希
当容量从 n 扩容为 2n 时,原来元素的哈希值 hash 并不用全部重新计算,只需要看它的“新增那一位”是 0 还是 1。
假设原容量是 16(即 2⁴),扩容后是 32(2⁵):
-
原来索引是
index = hash & 15(0b1111) -
扩容后索引是
index = hash & 31(0b11111)
也就是说,只需要判断第 5 位是 0 还是 1:
-
如果是
0,那么元素还在原来的桶里 -
如果是
1,它就被挪到 “原位置 + 原容量” 的桶里
这就是为什么源码中有一段逻辑是这样的(JDK 8 中):
if ((e.hash & oldCap) == 0)
e.next = newTable[j]; // 留在原位置
else
e.next = newTable[j + oldCap]; // 移到新位置
2. 节省大量计算成本
因为不需要重新计算哈希值,也不需要重新做 mod 操作,仅靠一位 & 运算就能决定新位置,所以扩容时的计算量大大减少,效率很高。
总结一句话:
使用 2 的 n 次方作为数组大小,可以让
HashMap扩容时通过判断哈希值的某一位,快速决定元素是否需要移动位置,且不需要重新算完整的哈希和取模,这就是“重哈希定位更高效”的核心原因。
以上就是“重哈希定位更高效”的核心原因。